
In this article, we’ll explore the exciting world of data modelling in DynamoDB and uncover the power of this NoSQL database. Modelling with DynamoDB requires a completely different approach compared to relational modelling. I will look at a simple example to demonstrate this, and then go over some things you need to think about if you’re trying to decide whether to use DynamoDB in your work.
What is DynamoDB?
DynamoDB is a proprietary, fully-managed NoSQL database owned and run by AWS. It was originally developed as an in-house solution to fix problems Amazon were having with their infrastructure. At the time, they were using Oracle as their database, but the large amounts of data they were storing and manipulating made their database joins grind to a halt. In 2007, they released a white paper detailing the implementation of Dynamo, and this was followed five years later by the release to the public of DynamoDB.
DynamoDB’s core design principles reflect the problems Amazon was solving when the system was originally architected:
- Key-value/document storage – DynamoDB is not relational. Moving to a noSQL approach avoids issues with relational joins when working with extremely large datasets.
- Flexibility – the use of key-value storage also makes DynamoDB very flexible. Unlike relational databases, a table can store multiple types of data and its schema can be altered as needed.
- Scalability – DynamoDB is intended to scale automatically and seamlessly as the quantity of the data it works with increases.
- High performance – queries run extremely quickly and are largely unaffected by the amount of data being stored and queried.
- HTTP API – the database is queried using HTTP calls, which avoids some of the problems with managing persistent connections that other databases experience.
In addition, the fact that DynamoDB is fully managed means that you don’t need to handle infrastructure, and high availability is built into the system.
Data modelling and DynamoDB
Data modelling is like creating a blueprint for your application’s data – a crucial step in building a strong foundation for your database. It identifies how data will be represented, as well as its flow in and out of the database.
Relational databases
With relational databases, data modelling is well-defined and understood. For a particular pattern of data, there is usually an established way of modelling it. For example, a one-to-many relationship is almost always modelled using the id of the parent as a foreign key on the child entity.
In the example below, each client can have multiple addresses, and addresses are linked to clients using the client id, represented as a foreign key on the address entity.

duplication and redundancy. This helps data consistency and integrity, as the aim is to only ever have one copy of each piece of data in the database. To facilitate this, data is split into small tables, and when a query runs, the database joins these tables together to form the required sets of data to query against.
DynamoDB
With DynamoDB, there are usually multiple approaches to modelling a particular set of entities and, as a key-value/document database, there is no such thing as a relation or join.
The simplest approach is to model each entity type as a separate table, and manually join the required data for a query by making a number of individual database calls. This works well and is flexible. However, it requires unnecessary calls to the database, slows down query speeds and increases costs.
The alternative is a single table design. In this case, data is denormalised, copying it into all of the places it is needed based on the database’s expected access patterns. Having all data in a single table minimises the number of database calls required, reduces costs and increases query speeds. This is the method recommended by Amazon itself, as it forces you to think in a non-relational way.
Modelling decisions in single-table design are influenced by a large number of factors including data size and complexity, how often it is accessed and updated, considerations around how other design decisions have been made, and the general data model of the system. You also have to think about sorting and filtering data as, unlike relational databases, these requirements have to be incorporated into the data model during the design process.
Ask a hundred developers to produce a data model and schema using a relational database, and the vast majority will give you very similar results. Do the same with DynamoDB, and the results will be much more varied, as there isn’t necessarily a ‘best’ approach.
As an example, let’s take a simple one-to-many relationship similar to that which we used above and look at two alternative ways of modelling it in DynamoDB.
Complex attribute on the parent entity
This approach works well when the child entity is relatively small, its data doesn’t need to be directly queried and doesn’t change much, and the number of children related to a particular parent has an upper bound. For example, modelling clients, each with multiple phone numbers.
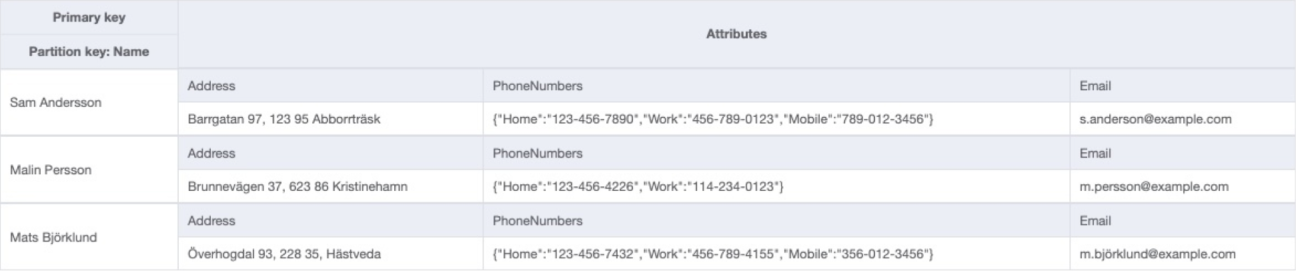
The phone numbers of each client have been modelled as maps, with the type of number as the key and the number itself as the value. Querying for ‘Malin Persson’ returns their full details including their list of numbers. However, as the numbers are not included as part of the primary key, you cannot use their values to filter or sort the results as part of the initial query. You can use them as part of the query’s filter expression, but this filtering takes place after the initial fetch of the data from the database.
The composite primary key with multiple item types
This is a more flexible pattern where both the parent and child entities are modelled as part of the same item collection. The inclusion of attributes from the child entity in the sort key allows you to use those as part of filtering and sorting before the data is fetched from the database.
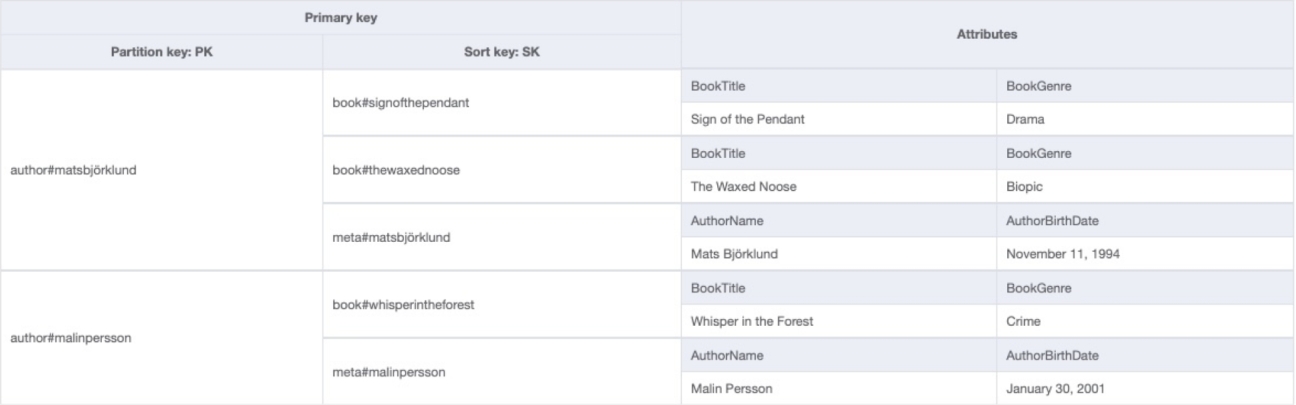
In the above example, you can retrieve an author and all of their books with a single query, as they have the same partition key. As the book title is included in the sort key, it can also be used as part of the query, for example finding the details of a specific book, sorting books alphabetically or filtering to show only those starting with a particular letter.
Things to consider when choosing your database
The skill set required
As we’ve explored in this article, the approach to data modelling with DynamoDB is completely different from that used with more traditional relational databases. There is not necessarily one ‘correct’ solution, making it much easier to get things wrong. The knowledge required to model with DynamoDB is also less prevalent, and it can be more difficult to source developers with the required set of skills and experience.
The complexity of application code
There is often an assumption that the flexibility offered by DynamoDB means you don’t need a schema. This can lead to major problems as your application grows and changes. A more realistic view is that the schema exists, but instead of being defined as part of the database itself, it’s enforced by the application code.
Denormalisation and the removal of relations also move complexity to the application. It becomes the developer’s responsibility to ensure data consistency in a denormalised database as data changes. This can be mitigated a little with sensible architectural decisions, but still needs to be kept in mind.
Flexibility when making change
Much of the work required with DynamoDB has to be done at the start of a project. Choices about how to model a system are incorporated into the primary key, secondary indexes and other aspects of a table’s structure, and it can be challenging to make changes further down the line. Adding the ability to filter an entity by a different attribute as part of a query might require a completely different modelling strategy, and this could impact all existing decisions about the way that a table was originally designed. You will probably find yourself using migrations more often, as they will be needed when you move data from one version of a table to the next.
This also raises the question of how compatible modelling with DynamoDB is with agile work practices. These emphasise the need to be flexible, responding as requirements change over the course of a project. If this is an issue, one option is to avoid moving to a one-table design until a project’s schema becomes established, and accept that queries will not initially be optimised. Keeping entity types in separate tables gives more flexibility as and when requirements change. The alternative, working with a single-table model from the start, is also a possibility. In the early stages of a project, data models are likely to be relatively straightforward, so changes might not have too much impact on the way tables are designed.
How easy the model is to reason about
DynamoDB tables can be more difficult to reason about than relational schema. Relational models generally each have a separate table for each entity type with very clearly defined relationships that are easy to map directly to an Entity Relationship Diagram (ERD). For example, given the ERD below:
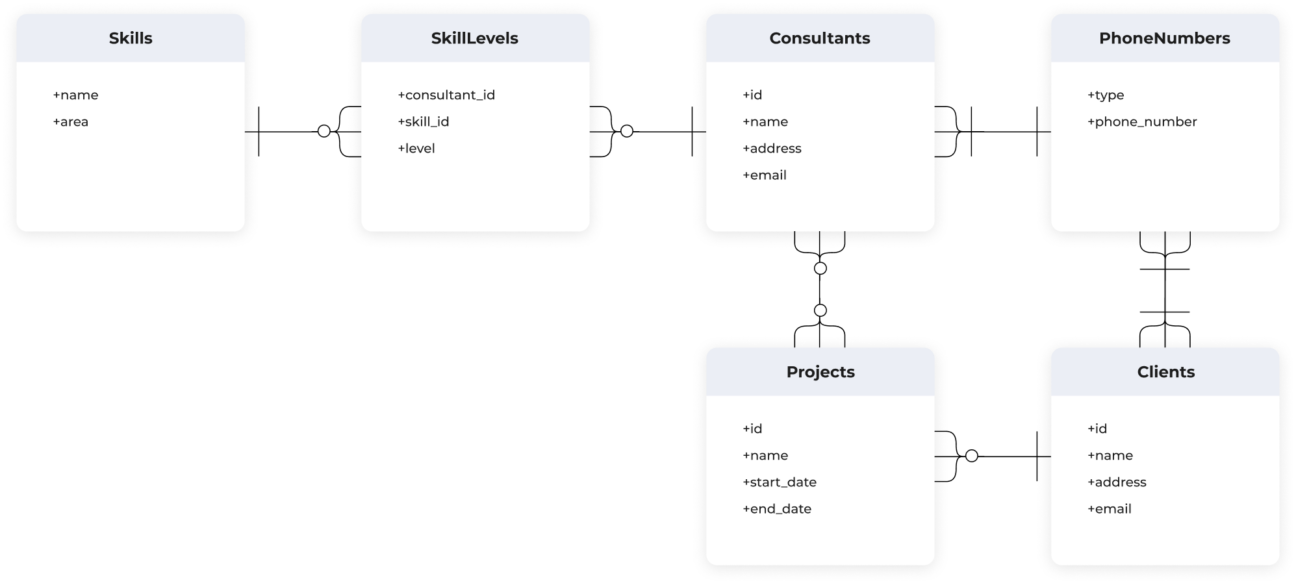
Here is a possible relational schema solution and you can clearly see how closely it follows the structure of the ERD itself:
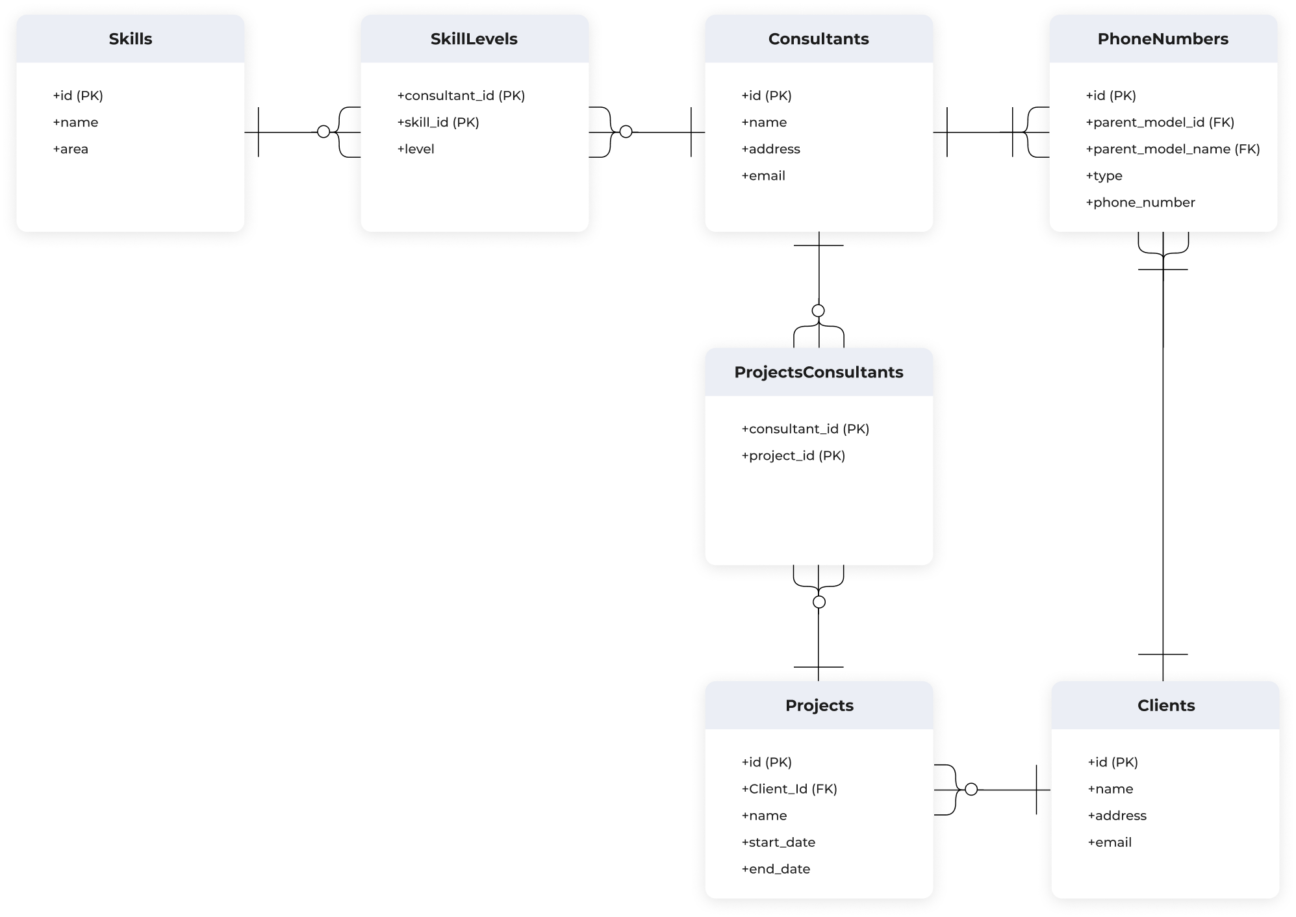
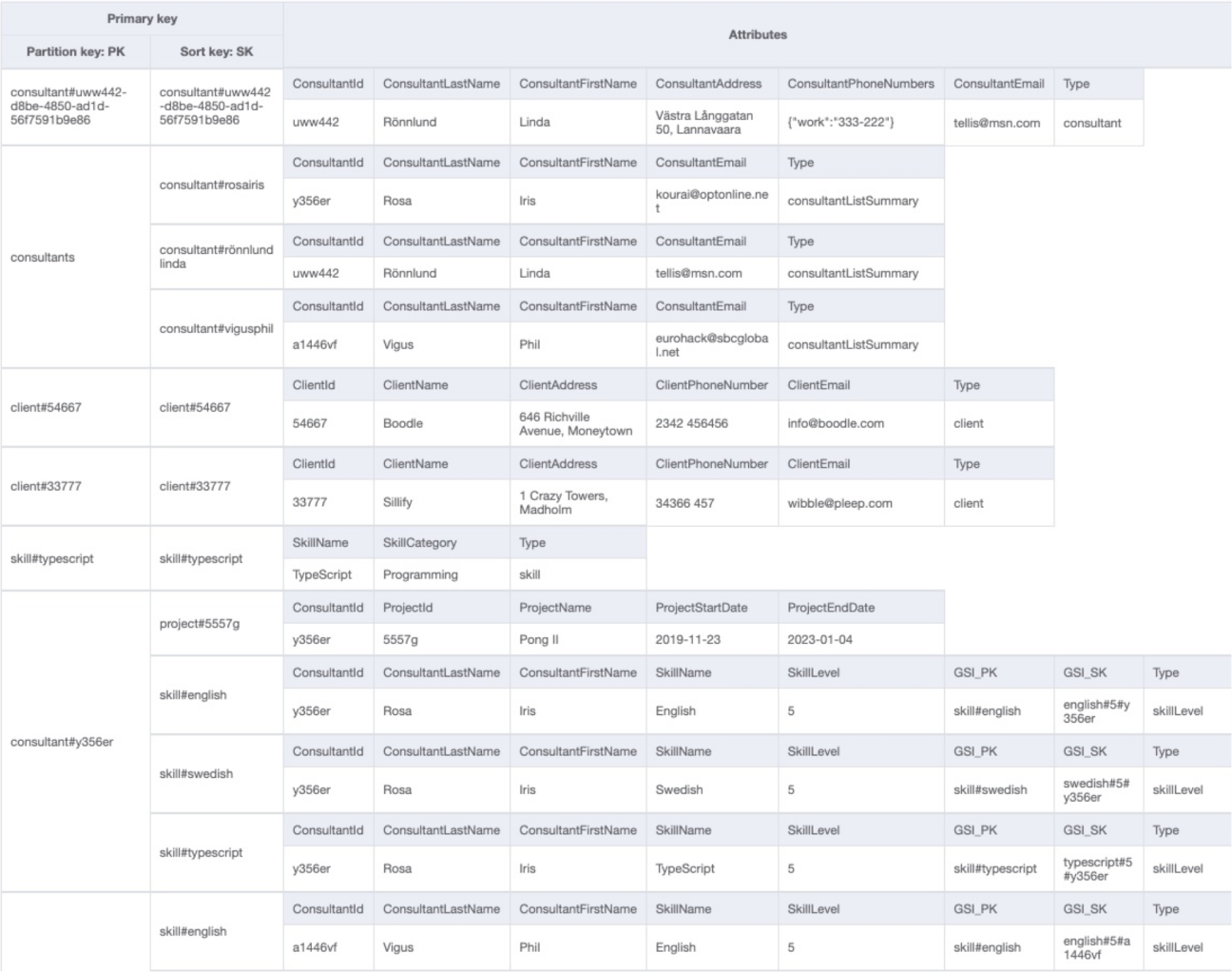
By contrast, here is part of a single-table DynamoDB design for the same ERD, and it is much more difficult to see how they relate to each other:
Compatibility with serverless architectures
One of the key characteristics of serverless architectures is their use of functions as a service, such as AWS Lambda. These typically run for short periods, but can still exist in large numbers at any one time, and they can create unpredictable workloads. Handling their database access with traditional, persistent connections in this context can become a problem, with connection pools being the most common approach.
The fact that DynamoDB is accessed through HTTP calls offers a much simpler solution. A table can easily handle large numbers of concurrent requests and is limited only by the provisioned capacity of the table. This makes it ideal for the more ephemeral connections you tend to need with serverless architecture.
Conclusion
DynamoDB is excellent at what it’s designed to do. It’s fast, flexible regarding what you can store in a table, scales seamlessly as the size of the data stored increases, and is accessed through HTTP calls. Using some of the techniques discussed in this article, it allows you to model complex ERDs, and overall these qualities make it an excellent fit for use cases such as serverless frameworks or microservices.
However, it isn’t a silver bullet, and working with it comes with some issues that you need to be aware of. The skill set required is completely different to that needed for working with relational databases, code becomes more complex, and models are harder to change.
As with many things in software development, there is no right answer here. You have to consider your particular use case and decide whether the pros of using DynamoDB outweigh its cons. However, there are certain things DynamoDB does exceptionally well, and it should definitely be part of your developer toolkit.
Phil is a backend developer who loves working with Java. He is happiest when he’s solving complex problems with simple solutions or sharing knowledge with others, and when he’s not working he spends his time exploring Stockholm.

