AI is the future. This is not a controversial statement. In fact, it’s one I’m sure you have heard a lot. We are using AI to enhance user experience, to mitigate risk, to sell ads, and maybe one day, to drive our cars. Between the reality of AI and the proclamation that “Data Scientist will be the sexiest job of the 21st century,” we have all heard the hype.
However: 80% of machine learning projects fail to make it into production. And that’s likely a low estimate. This is an astounding number when you consider the cost of a machine learning project failing. I mean the literal cost; data scientists are a high cost human resource, and the cost of training a machine learning algorithm can be non-trivial.
On one hand, we have the promise of data changing your organization, and honestly, it really can. The value of all of the FAANG companies relies on machine learning of one flavor or another. On the other hand, the majority of projects are never being put into production, and therefore, are never adding business value. How can we reduce this cost? What can we do to ensure that our machine learning projects are more likely to be successful?
The short answer: you can never be 100% sure that the project will be successful and we shouldn’t shy away from failure. You can learn a lot from failing! Which is what this article is all about. I’m going to go through five rules you can follow that will improve the chances your projects are successful. And then, because I like humiliating myself, I’ll tell you an example from my own career when we violated that rule and the project failed.

1. Know Your Product
This is the most consistent mistake I see data scientists make. Over and over and over again. They develop a machine learning algorithm that they think is really cool, and then are puzzled why the product team doesn’t think it’s cool enough to integrate in the product. The old “if you build it they will come” idea. This RARELY works.
For example: when I worked at a fintech, we had a project that we thought was so cool. For each transaction, we wanted to have the option for the customer to see exactly where the transaction took place. We integrated openstreet maps, and wrote a predictive algorithm to determine in which store location each transaction took place. We then spent time building the product, so that we could deploy it to our dev environment and demonstrate how cool it would be!
But here’s the thing: the product team didn’t want it. Being able to see where you made a transaction on a map added very little to the customer experience. By using openstreet maps, we had a pretty hacky work around, and if we had tried to do it properly with google maps (which we would have needed to do to scale in production), it would have cost WAY too much. The cost was never going to offset the gain in experience to the customer.
We spent a year developing an algorithm that the product never wanted in their product. We built it. They didn’t come.
Don’t:
Build an algorithm and then approach the product team to see if they are interested in integrating it.
Instead:
Learn about the product, and think about how your data can improve it. Talk to the product owner about the possibilities. Figure out which ones they want the most, and will add the most value to their product. Then build that algorithm.

2. Know Your Data
There is this concept that you can just take data, throw it into a magic data box and business value will just fall out. And you can do that! But as the old saying goes: if you put garbage in, you’re going to get garbage out. This is true for machine learning projects as well.
The bad news: most real world data is VERY messy. The good news: there are lots of techniques that have been developed to deal with messy data. But that only works if you get an understanding of your data, and what it means. Once again, this will involve getting cozy with the product (embrace it, these are going to be your people). But if you try to throw your garbage data at an algorithm and then optimize for accuracy… may God have mercy on your soul.
For example: At one point in my career, I was working at a fintech where we had a siloed data team. And we had transaction data for all of our users, and every single person who joined the team had the same idea: we should cluster our customers. We can take the transaction data as the feature space and then use the clusters to help marketing. Or to upsell products. It’ll be amazing!
But here’s the thing: everyone spends their money the same way. They pay rent and bills. They go shopping a bit. They buy food, and go to restaurants. Sometimes they make big purchases. How much they spend on each of these items varies, but that is only one feature and a continuous one at that. So despite much effort, we were never able to get our customers to cluster.
Despite this, every single person on the team tried. From the intern right up to the CDO. Finally, it became an initiation step: new people would join the team, tell us they were going to cluster. We would give them a high-five and wish them well. A week later, they would come back to us with the same result. I guess it wasn’t a failure in that we all had a shared experience. But it wasn’t a success by any stretch of the imagination.
Don’t:
Go too far down a rabbit hole of building a model, or a model pipeline, or a dashboard, etc., until you know the data. You don’t know what patterns exist in your data until you look, so go look. That’s the job!
Instead:
Spend time doing exploratory data analysis, and see what the data looks like. Learn about the features you have. Think about engineering new ones, and make those transformations happen. Ask the product team when you see patterns you don’t understand, or distributions that could be informative. There is a movement afoot in AI to be more data centric, and the reason is because it works. Turn your garbage into gold BEFORE you put it anywhere near an algorithm.
3. Learn to Love Cleaning Data
As I mentioned in the last rule, real world data is messy. I was at a hackathon put on by one of our sister companies, and the students competing were given real world data and asked to find insights. One student group told me “the question wouldn’t have been asked if there wasn’t a pattern here!” to which I responded “oh no! No one knows what the data looks like, that’s your job.” They were astounded at how messy the data was, and it was a relatively clean data set tbh.
And I think it’s the thing that surprises students the most when they start interacting with data: 80% of your time will be spent cleaning data. And there are weeks when that’s a small estimate. But if you don’t love cleaning data, you’re never going to make it into something usable.
For Example: In a previous role I was working on an ecommerce app. We had a buy now, pay later product within the app, such that customers could make a virtual card within the app and use it in any store on the internet (more or less). My team was responsible for making sure that customers weren’t abusing this product by making a card they had no intention of using correctly. And one idea the product team had was to match the merchant name that the customer put in when they requested the virtual card with the name that visa (our card processor) reported was where the customer used the card. If it matched or not could be a feature in our model to help predict that the customer wasn’t abusing the product!
Here’s the problem: merchant data from card processing companies is some of the messiest text data you’re likely to see. One of the biggest online stores our customers used was Amazon. Do you know how many different merchant names when processed are actually just Amazon? I counted at one point: there were 64 different ways within our data set, that all meant the customer used the card at Amazon.

So I created a mapping dictionary, such that whenever we saw any of these 64 different text strings we would know it was Amazon.
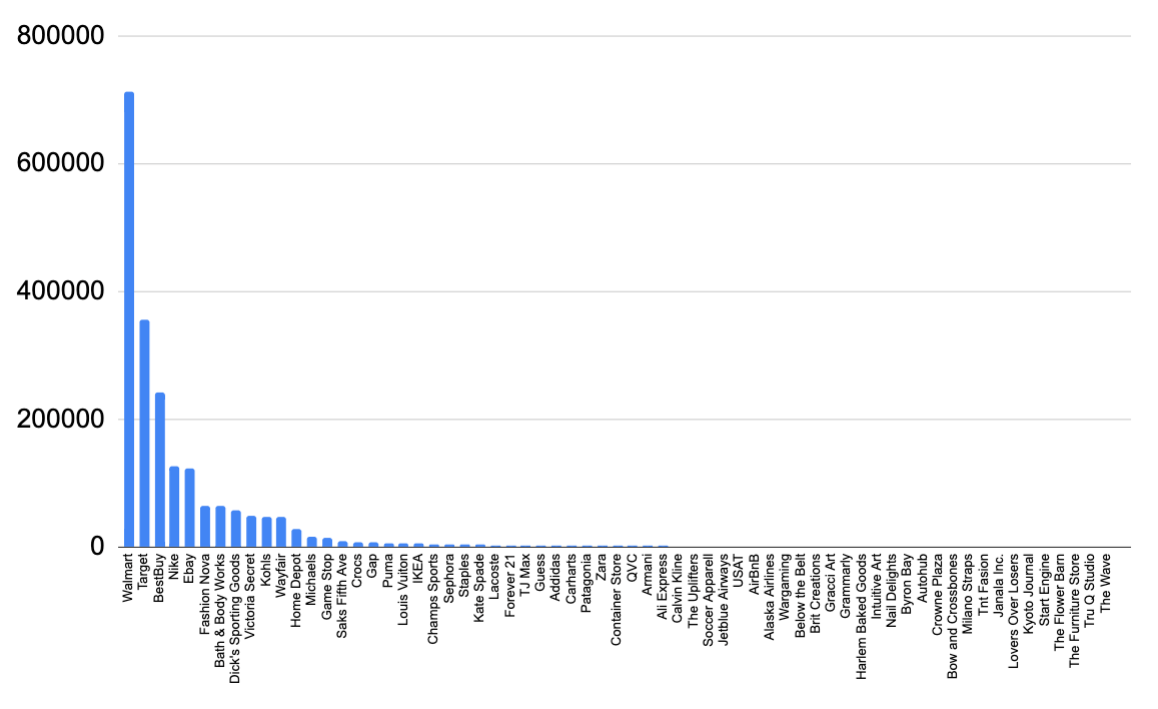
But there were over 100,000 different online stores our customers used, and we can’t do this kind of mapping with all of them. However, if we only take the biggest stores, this covers ~80% of our use case, so that’s what we did. This was all a lot of work, but the new feature (matching merchant names from the point of virtual card creation to the point it was used) really helped the algorithm identify abusive behavior, and overall made our product more profitable! We took messy data and made it into something that provided value. But it took effort.
Don’t:
Throw data in the model and hope for the best. The best is never going to happen in reality.
Instead:
Check data quality, missing values, imputation, skewed variables, balance, and text strings. There will be duplicates, and total junk in your data set. Find it, and fix it!
4. Simple is Better than Complex
Everyone wants to work with neural networks, and make crazy cool deep learning models. If I had a dollar for every time I had a young data scientist tell me that, I would be VERY rich. But the reality is: 90% of machine learning algorithms currently in production are not deep learning models. There are times when you will need deep learning to get a good result: computer vision and image processing, and SOME (but not all) natural language processing (let me tell you about TF-IDF, my friend) to name a few. But for almost every other machine learning use case, not only will neural networks cost more to train, but they are not going to perform as well as other algorithms.
For example: I was working at a fintech company where we offered loans to customers. We had a wealth of internal and external data sources about past customers and which had paid us back and which hadn’t. We used this data to make a binary classification model: will someone in the future pay us back; yes or no. My manager at the time was a network guy, and convinced that neural networks are always the answer no matter what the question was.
And I lost a bet to said manager.
So I had to deploy a trained neural network to the development environment to test if it was better than the gradient boosted tree algorithm I had already deployed there. Let me tell you: in every conceivable metric, the gradient boosted tree algorithm performed better. It took less time to train, cost less to tune the hyperparameters, had a better response time, handled the increased load with fewer computation resources, and was more accurate on the test data. It wasn’t even a competition.
Now, that may change over time. There are a lot of advances being made in applying networks to tabular data (looking at your tablet), that improve their performance. But it will still be true that you will want to start with something simple before investing time and effort into a more complex algorithm. Can you use a samurai sword to cut a sandwich? Yes. Do you need to? Probably not.

Don’t:
Jump to the latest and greatest advancement in the field. You may waste time and effort going too far down the wrong path.
Instead:
Try a simple solution. Will a few rules work? A linear regression? A gradient boosted tree algorithm? It will cost less time to train and develop, and you’ll have a baseline to compare later advancements to.
5. Perfection is the Enemy of Finished
This applies to all coding jobs, but is especially common in data science. There is a balance. You need your code and algorithms to be good enough not to cause massive technical debt in the future. But this isn’t the Sistine Chapel, it doesn’t need to be a masterpiece. Your machine learning project doesn’t need to be perfect, it needs to be finished. My graduate advisor used to say that: no one cares how much you start things, they only care how often you finish things. Be a finisher!
For example: I worked at a neo bank where we lent larger loans based on a customers salary-their monthly expenses. We had a classification algorithm that identified salary, and bills to estimate the overall amount we would be willing to loan customers. Salary was the most important feature, and one we really wanted to be good at identifying.
But our data scientist became a little too fixated on making the salary classification perfect. He asked the team for help labeling more and more training data. Then he did a full refactor of the code 3 times to maximize the new libraries that were coming out and made sure his code was squeaky clean. All of which was great! But it meant it took 18 months to get his algorithm into production.
The rest of the product team was ready to deploy it within 6 months.
What he should have done instead was put the first “not perfect” version into production and test how it performs on real data. Before business people come at me: you can put an algorithm into production without it making decisions. It makes the predictions and saves them, then you can look at how it performs for real without taking on a huge risk associated with an imperfect credit model. Then once you have the feedback on how it’s performing THEN you make those improvements that make it closer to perfect.
Don’t:
Keep pushing marginal improvements over testing your algorithm in production!
Instead:
Find something good enough and get it out the door. You can iterate and improve on the next version based on that valuable feedback you gain.
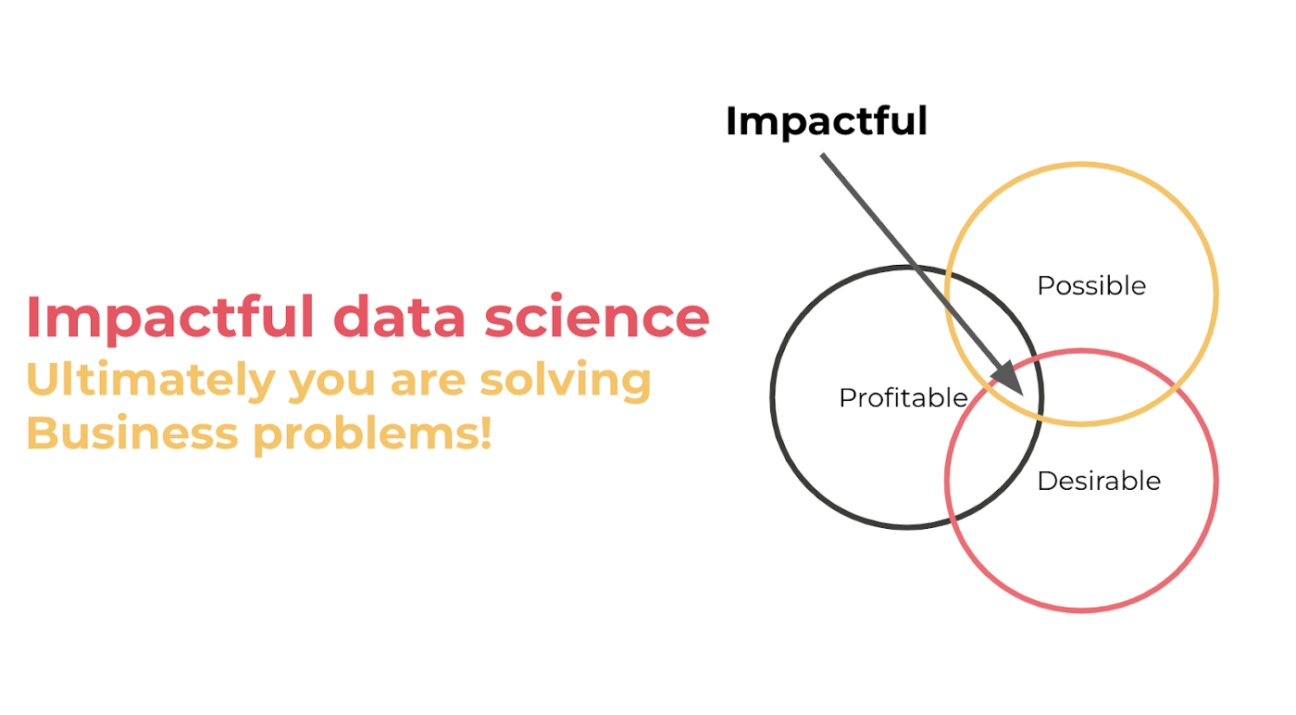
Ultimately AI needs to Create Business Value
If you’ve worked with AI, the above failures are going to look very familiar for you. Which is one of the reasons I felt kind of ok sharing some of the times I’ve failed. Plus: failure is only valuable if you learn from your mistakes!
So when starting your project, follow the above rules, but also think about: Is it possible? Is it profitable? Is it desirable? If the answer to any of these questions is a hard “No,” then you really need to rethink why you’re doing it.